5.4. Convergent Sequences
We start this new section with a closer look at our introductory sequence . Let us recall the table of values
with a detailed eye for the sequence members. First we note that each numerator is nearly twice the appropriate denominator, thus all sequence members are less than 2 in value.
The difference between doubled denominator and numerator however is constantly 1 so the sequence members' difference from the number 2 is steadily decreasing.
We see this clearly noting them in their decimal representation and visualizing them on the real line:
The tendency for 2 becomes also obvious when calculating the distance - i.e. the difference in absolute value - of sequence members to 2.
Take e.g. the 1000th member:
Thus the 1000th sequence member and all to follow (note: the sequence is increasing) is closer to 2 than 0.001.
However to ensure that this sequence approaches the number 2 it isn't sufficient to choose some sequence members by chance and calculate their distance to 2 as small.
The task has to be reversed instead: Are we able to prove that for each arbitrary distance
nearly all sequence members are closer to 2 than ?
We will show this for our example sequence. But to this end we first have to introduce a precise notation for the fact that 'a sequence
approaches a number g'.
The following definition is the base of all calculus.
|
Definition: Let be any sequence and . We call convergent to g (in symbols: ) if for each real there is a natural number such that
|
[5.4.1] |
If is convergent to g, we call g a limit of . In this case the sequence is convergent. Sequences with no limit are said to be divergent.
|
Consider:
Occasionally there is an advantage in rephrasing the definition of convergence. Obviously the distance of
to g will be less than if is at most
units away from g regardless if it is to the right or to the left.
That means has to be in an open interval centered at g with radius :
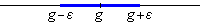
In this context we call these special intervals of g and restate the convergence condition as follows:
|
| For every there is an ,
such that .
|
[5.4.2] |
Now we can prove exactly that our initial sequence converges to 2:
|
Example:
-
Proof: Let be arbitrary. We need to find an so that all sequence members from on are closer to 2 than . Let us see what they have to contribute to fulfill this demand:
So we have: The distance to 2 of a sequence member is less then as soon as the index is more than .
This information enables us to choose an appropriate : As is unbounded (cf. [5.3.21]), we can take an such that . For all this implies: .
These n thus satisfy
.
|
Consider:
Although we now definitely know that we still can ask if has further limits. From the original definition we don't get any information on the uniqueness of the limit,
but it is easy to see that no sequence permits two limits:
|
Proposition:
|
Every sequence has at most one limit. |
[5.4.3] |
Proof: Assume and are two different limits of . Then their distance
is non-negative.
If we center at and at each an open interval with radius we get two -neighbourhoods with no common elements. (+)

But as we get from [5.4.2] a natural number such that all sequence members with an index are members of the first neighbourhood. Similar we see all members from an appropriate index onwards in the second neighbourhood.
Now set . The sequence member thus belongs to both neighbourhoods, in contradiction to (+).
|
So we know that convergent sequences have exactly one limit. So we may introduce a symbol that only shows the data of . If we say that g is the limit of and we denote this by:
, or more explicitely: .
The convergence e.g. may now be noted like this:
.
The question of convergence is always combined with the problem of divergence. From our alternative definition [5.4.2] we get a quite handy criterion for divergence.
|
Proposition:
-
| each -neighbourhood of g misses at most finitely many sequence members.
|
[5.4.4] |
-
| there is one -neighbourhood of g missing infinitely many sequence members.
|
[5.4.5] |
Proof:
|
1. ►
|
"": If is an arbitrary -neighbourhood of g, [5.4.2] provides an such that But that means that at most the sequence members
- and these are only finitely many - are missing in .
"": If , the neighbourhood will miss at most finitely many members, say . If we set all sequence members with will belong to . According [5.4.2] this proves the convergence .
|
|
2. ►
|
This is just the negation of 1.
|
|
The following examples will play an important role in our further studies. The third one, by the way, uses our new criterion for 'non-convergent'.
|
Example:
-
|
[5.4.6] |
|
For a given we take an . Then we have for all and thus
.
|
-
for each constant sequence
|
[5.4.7] |
|
If all sequence members with
satisfy
.
|
-
ist divergent
|
[5.4.8] |
|
We have to show: No real number is a limit of . But for each g the set is infinite, i.e. the special -neighbourhood misses infinitely many sequence members. With [5.4.2] we conclude: .
|
|
Even without our proof the divergence of is quite obvious: The natural numbers 'break away to the right', they can't concentrate on a fixed point in the end.
There are many divergent sequences with a similar behaviour. The next example however shows a divergent sequence that is bounded.
In that case divergence is due to the fact that the sequence can't decide where to go.
|
Example:
is divergent
|
[5.4.9] |
Proof: Again we use our criterion [5.4.2].
The special -neighbourhood
of 1 misses infinitely many sequence members, namely all with an odd index. Thus at the very moment 1 is no limit of .
Now, if g is an arbitrary real different from 1, we have: . As r is the distance of g to 1 the neighbourhood will miss the number 1 and therefore all the infinitely many sequence members with an even index. So g is no limit of either.
Having no limit at all this sequence is divergent.
|
The convergence of a sequence describes the behaviour of the sequence members 'in the long run', so the 'first' members are of no significance in this respect.
More precise we have the following:
|
Proposition: Let be an arbitrary sequence. For each the following equivalence holds:
|
[5.4.10] |
Proof:
"": Let be given. As we get an such that for all . From we have for these n more than ever: . This proves .
"": Let's start again with an . Now we have , so we get an such that for all . As all satisfy we have for these n: . Thus the convergence is valid.
|
From our examples we see that the basic task in proving a certain convergence is to solve the inequality for n. With more complicated sequences this leads fairly quick to unsolvable problems. It might be helpful to note that it isn't necessary to solve the inequality equivalently.
It is rather sufficient instead to squeeze down the distance beneath using the estimating technique. We illustrate this in our final example.
The next section will provide more comfortable utilities that often will replace efforts like the following.
|
Example:
-
Proof: For an arbitrary we take an . Then we get for all
:
|
|
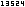 |
|